De entre las etapas de la codificación de imagen y vídeo, la cuantización es la única en la que se…
Continue Reading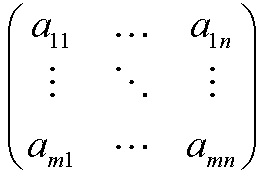


De entre las etapas de la codificación de imagen y vídeo, la cuantización es la única en la que se…
Continue ReadingIn probability theory, the normal (or Gaussian) distribution is a very common continuous probability distribution. Normal distributions are important in…
Continue ReadingDe cara a la escritura de la Tesis, en esta entrada voy a explicar cómo se calculan correctamente los CSF…
Continue Reading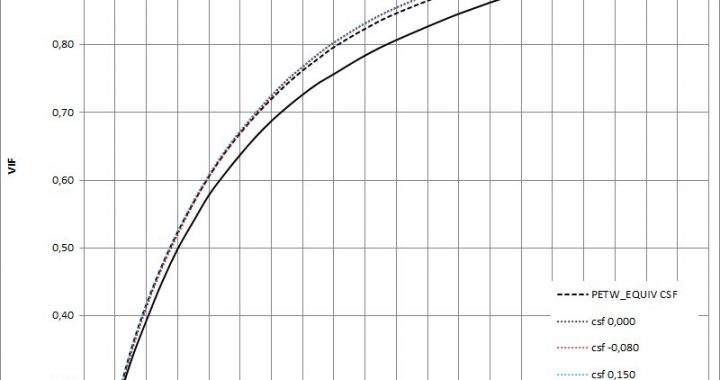
Corrección del cuantizador en PETW Tras ver las diferencias en las curvas R/D entre el PETW y el S_LTW y…
Continue ReadingLa implementación correcta del filtrado para que no amplíe el tamaño de las subbandas se debe a la aplicación de…
Continue ReadingParece evidente que la VIF es la métrica que mejor se ajusta (de las estudiadas) a la calidad subjetiva tras…
Continue ReadingCuando esté realizado el rate-control uniforme tras la ponderación/cuantización perceptual se supone que tendremos una q que ajustará al rate…
Continue Reading