De entre las etapas de la codificación de imagen y vídeo, la cuantización es la única en la que se…
Continue Reading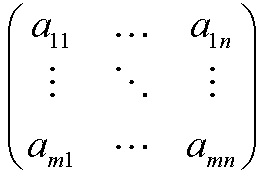


De entre las etapas de la codificación de imagen y vídeo, la cuantización es la única en la que se…
Continue Reading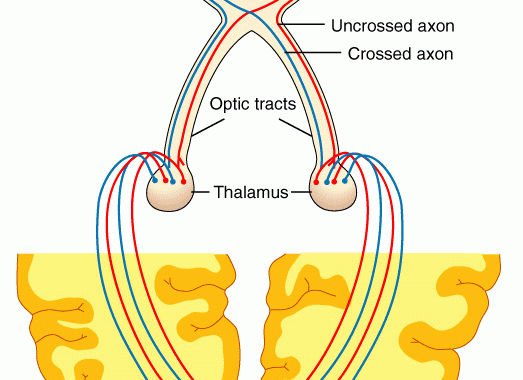
Todo aquello que es perceptualmente redundante puede ser eliminado. Estas son las características fundamentales del sistema visual humano (HVS) que…
Continue Reading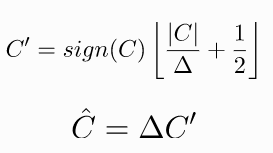
Here is some formulation for some of the most widelly used quantizers in image and video compression standards. Not only…
Continue ReadingDe cara a la escritura de la Tesis, en esta entrada voy a explicar cómo se calculan correctamente los CSF…
Continue ReadingCSFs Referencias a distintos modelos matemáticos de la Contrast Sensitivity Function.
Continue Reading